[Deep Learning 6] 합성곱 신경망
어째 요즘따라 쓰는 글이 길어지기만 하고 있다. 물론 있는 코드 없는 코드 다 싹싹 긁어서 포스팅을 하기 때문에 강제로 길어지는 바도 있다. 하지만 너무 오래 걸리다보니 나도 작성하고나면 진이 빠지는 경우가 많은 듯
그래서 이번 글은 코드보단 이론 위주로 설명하려 한다. 일단 이번 7장은 코드가 적기도 하고, 왠만한 코드를 다 선택사항으로 두기도 했다. 또 CNN 설계의 파트는 사실 라이브러리(keras, tensorflow)로 진행하는 것이 현명하기에, 굳이 모든 코드를 이해할 필요는 없어 보인다.
그래서 이론 위주로 설명하고 이해해보았다.
합성곱 계층
딥러닝이 적용되는 분야는 크게 두 가지인데, 이미지 인식과 자연어 처리이다. 이중 이미지 인식 분야에서 압도적으로 사용되는 방식이 합성곱 신경망(CNN)이다. 이에 대한 설명은 후술하도록 하고, 먼저 합성곱이 무엇인지에 대해 알아보자.
기존 Affine 계층이 갖는 문제점이 있는데, 입력 데이터의 형상이 무시된다는 점이다.
왜 x_train의 형상이 (60000, 784)였는지 기억하는가? 6만 장의 데이터가 28*28의 2차원으로 표현되는데, 이를 1차원으로 축약하는 과정에서 2차원 데이터를 일렬로 쭉 늘어뜨렸기 때문이다.
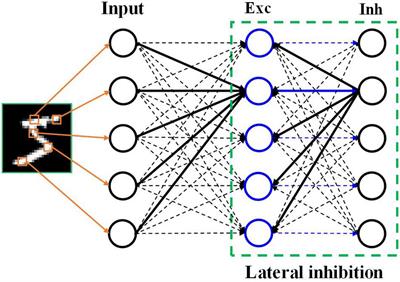
이러한 방식을 완전연결 계층(FC Layer; Fully Connected Layer)이라고 하는데, FC Layer는 분류/회귀 등의 작업에서 ‘최종 예측’이라는 1차원 벡터값을 출력하는 것이 효과적인 레이어이다.
그런데 오늘 할 이미지 인식(image recognition)을 FC Layer로 진행할 경우, 본래 2차원 데이터에서는 서로 상하좌우에 있던 픽셀들이 1차원으로 축약되는 과정에서 ‘위치의 정보’를 잃게 된다.
하물며 오늘 다룰 CNN은 이미지가 3차원(배치처리 과정에서는 4차원)이다.(이미지가 RGB로 표현되면서 channel이 3개가 되기 때문) 따라서 FC Layer로는 3, 4차원 데이터가 지니고 있는 공간의 정보를 무시하게 되면서 데이터의 형상에 지닌 정보를 살리지 못한다.
그래서 이를 해결하기 위해 합성곱 계층(Convolution Layer)이 제안되었다. 합성곱 계층에서는 데이터를 특징 맵(feature map)이라고 부르는데, 입력 데이터는 입력 특징 맵, 출력 데이터는 출력 특징 맵이라고 부른다. 근데 그래서 합성곱은 뭔데?
합성곱
과거에 봤던 영상인데 합성곱에 대한 모든 것을 간략하게 다 소개한 좋은 영상이라 여기에도 남겨본다.
합성곱(convolution)은 흔히 ‘필터 연산’이라고도 부르는데, 이 필터는 ‘커널(kernel)’이라고도 불린다. 컴퓨터 구조의 커널과는 다른 뜻이다.
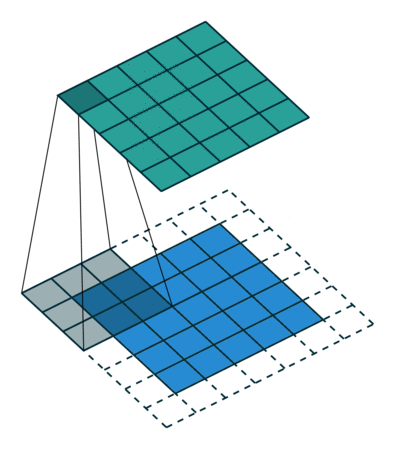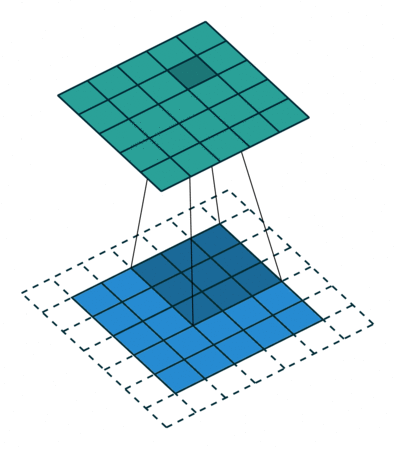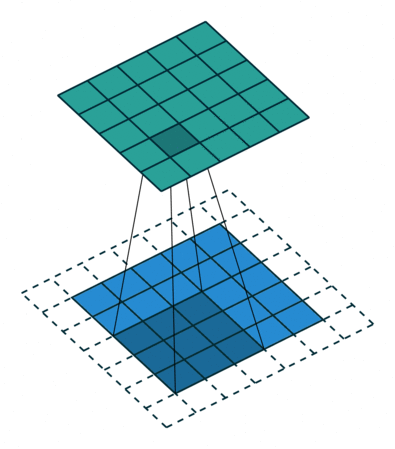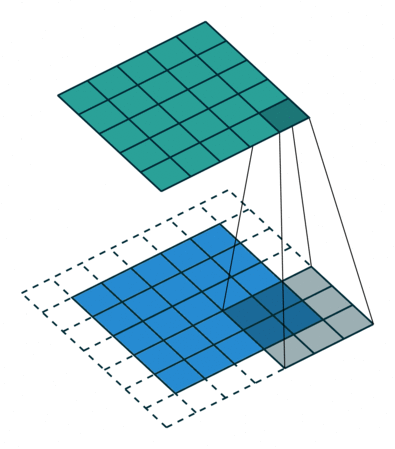
위의 gif처럼 필터의 윈도우가 일정 간격(보폭, stride)으로 이동하며 FMA(단일 곱셈-누산: 아다마르 곱 결과를 모두 더함)을 한 값을 행렬의 해당 장소에 출력하는 과정을 합성곱(컨볼루션)이라고 한다. (위의 예는 패딩이 1씩 추가된 형태이다)
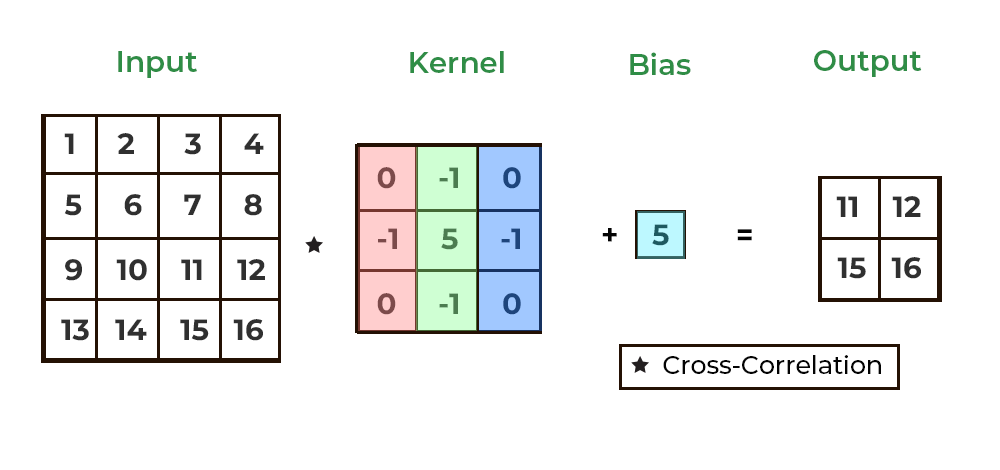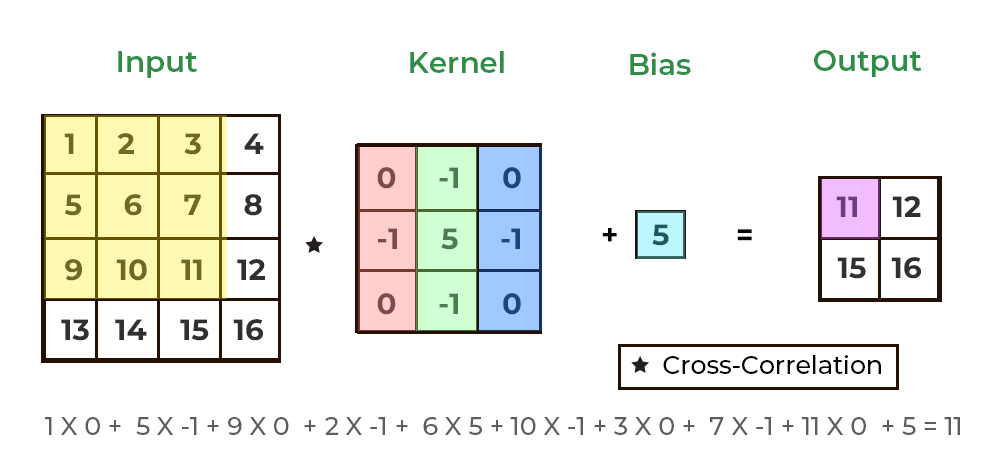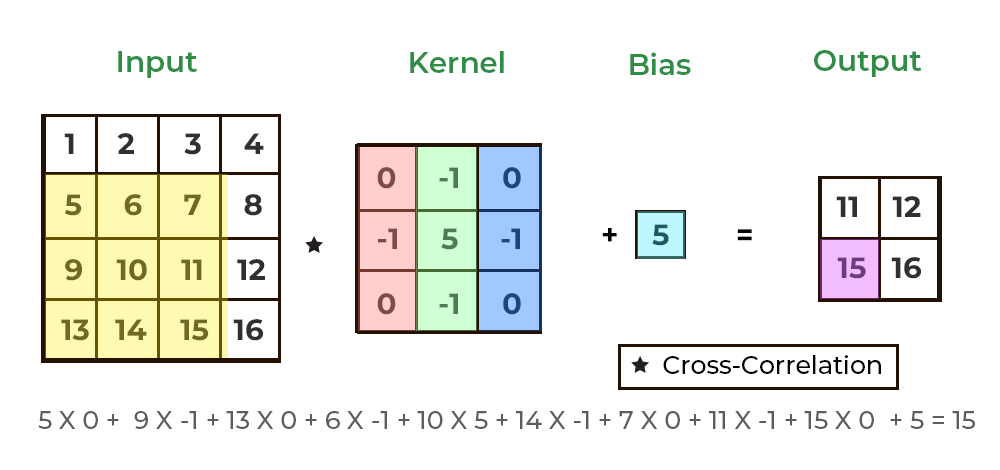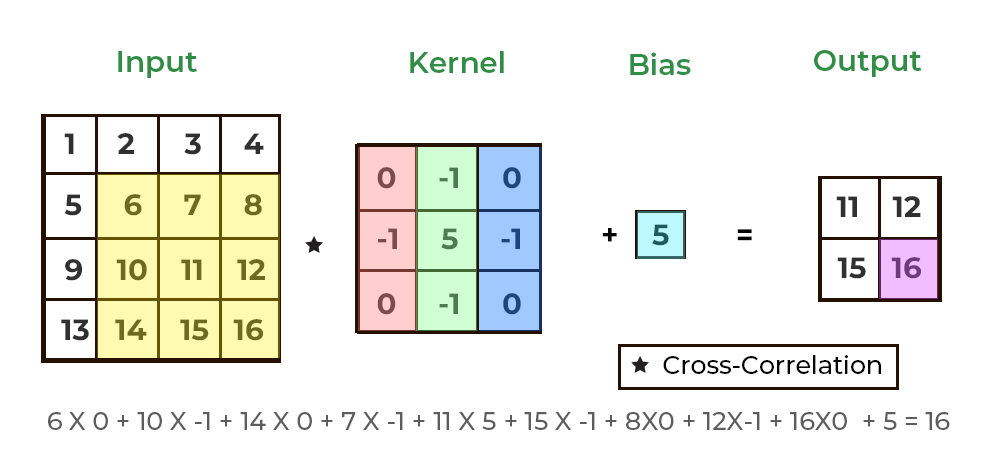
위의 gif는 가중치 행렬인 필터에 편향까지 적용한 식을 보여준다. 이때 편향은 브로드캐스트로 적용되어서 스칼라 값을 입력해도, 자동으로 행렬로 확장되어서 행렬의 합으로 처리되게 된다.
패딩
그런데 바로 위의 예에서 입력 특징 맵과 커널의 크기에 비해서 결괏값(출력 특징 맵)의 크기가 2*2임을 볼 수 있다. 이게 무슨 뜻이냐? 한 데이터가 필터를 통과하여 나왔을 때 그 크기가 줄어들은 것이다.
이것이 반복되면 결국 출력되는 행렬은 점점 크기가 줄어들어 스칼라로 소멸할 수도 있고, 너무 많은 정보가 축약되면서 오히려 데이터를 처리하기에 불리해질 수 있다. 또한 커널을 입력 특징 맵보다 크게 잡을 수가 없으니 무한히 가면 결국 모든 데이터는 하나의 값으로 요약되어 버린다.
이렇게 형상과 정보의 손실을 막기 위해 마치 택배 상자의 뽁뽁이처럼 input을 (특히 0으로) 감싸주는 방식이 등장했으니 그것이 패딩(padding)이다.

다음을 보면 본래 입력 특징 맵은 3*3이었지만, 상하좌우에 1씩의 패딩을 줌으로써 덩치가 부풀었다(겨울에 입는 패딩과 같은 역할).
따라서 입력 데이터가 5*5인 것과 같은 효과를 보여 출력 데이터도 이에 맞춰 크기가 커진 것이다. 패딩은 이렇게 출력 데이터의 크기를 조정할 목적으로 사용된다.
스트라이드
컨볼루션의 또 하나의 특징은 보폭을 정할 수 있다는 의미이다. 앞서 다룬 학습률(learning rate)이라는 뜻의 보폭(step size)이 아니다.
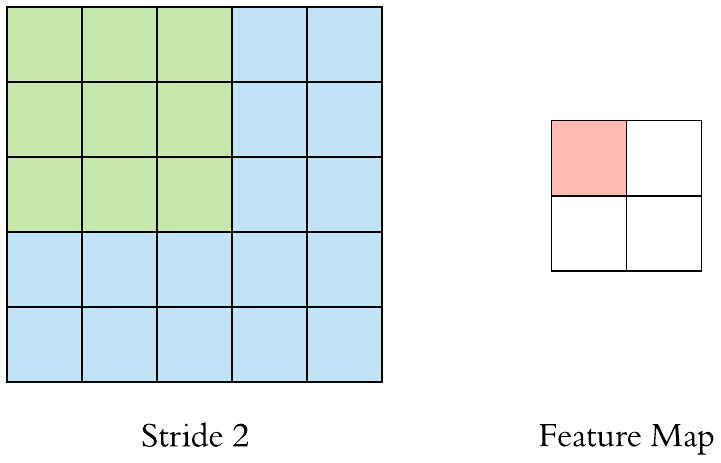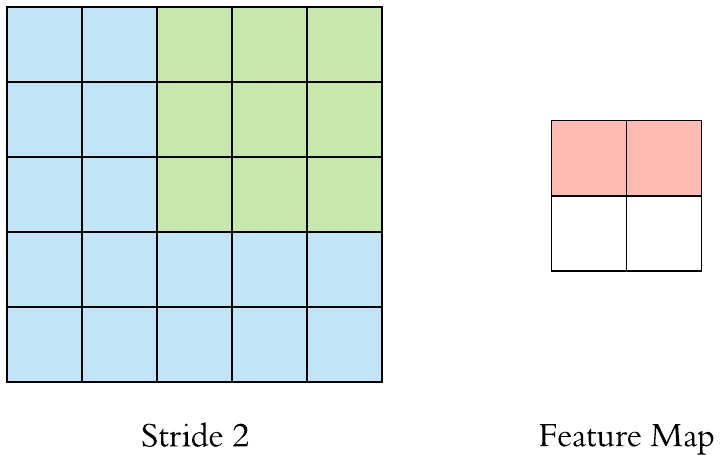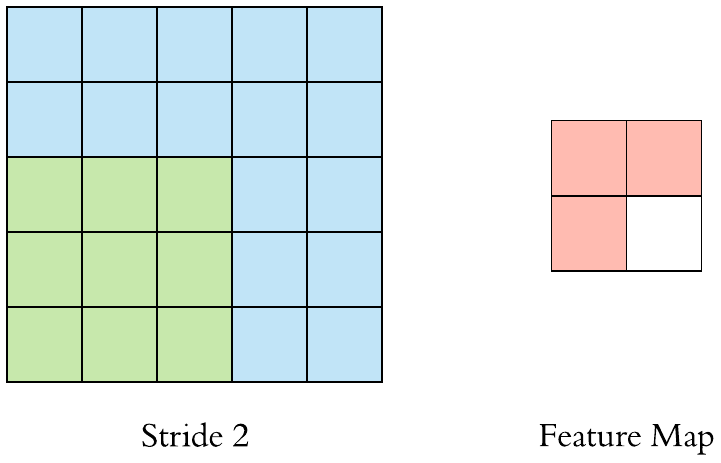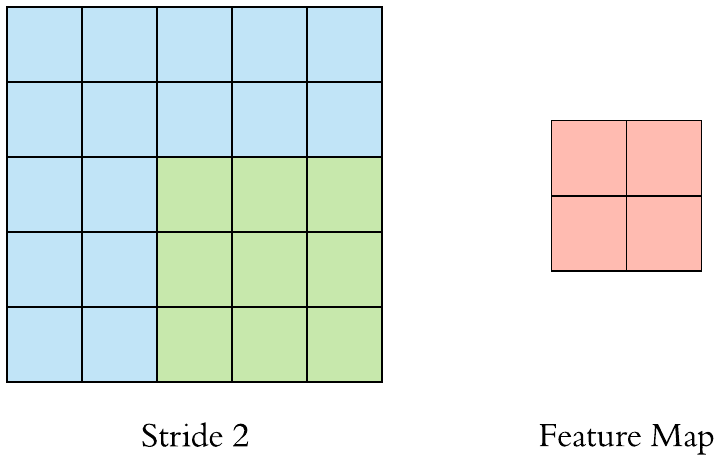
다름과 같이 필터를 움직이는 정도를 한 칸이 아닌 두 칸으로 지정할 수 있다. 이 경우 가로 방향과 세로 방향의 움직임이 모두 2칸씩 움직이게 된다. 이것을 스트라이드(stride)라 한다.
영어로는 ‘성큼성큼 걷다’라는 뜻인데, 그것처럼 큼직큼직하게 필터가 특징 맵을 순회할 수 있도록 하는 방식이다. 패딩을 주면 출력 특징 맵이 커지는 것과 달리, 스트라이드를 주면 출력 특징 맵이 작아진다.
이렇게 출력 특징 맵은 입력 특징 맵의 크기 (H, W), 필터 크기 (FH, FW), 출력 크기 (OH, OW), 패딩의 폭 P, 스트라이드 S에 따라 크기가 바뀌는데, 다음과 같은 식을 따른다. (여기서 H는 Height, W는 Width를 나타냄)
\[OH=\frac{H+2P-FH}{S}+1\] \[OW=\frac{W+2P-FW}{S}+1\]가끔가다 스트라이드 S의 크기로 인해 정수가 나오지 않는 경우도 있는데(S가 분모이기 때문), 이때는 오류를 내주거나 반올림을 하는 등 여러 구현이 가능하다.
3차원 데이터 및 배치 처리
초장에서 말한대로 CNN은 기본 3차원 데이터를 순전파로 흘려보낸다. 이 데이터는 (C, H, W)로 나타내는데 여기서 C는 채널 수로 보통 3이다(RGB).

다음과 같이 각 채널의 데이터와 필터를 컨볼루션하고, 해당 컨볼루션 값들을 모두 더하여 최종 2차원 출력의 원소로 집어넣는 방식이다.
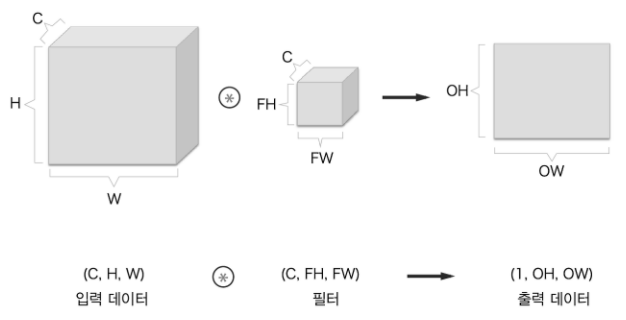
간단하게 블록으로 표현하면 다음과 같다. 그런데 Convolution 신경망은 편향도 더해야하고, 배치 처리로도 계산이 가능하여야한다(그래야 계산 속도가 빨라짐). 따라서 3차원 데이터 N개를 (N, C, H, W)의 4차원 데이터로 입력받고, 3차원 필터도 N개를 준비하여 데이터를 출력하는데, 이 모든 것을 요약하면 다음과 같다.
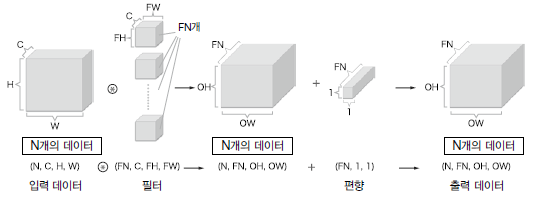
이 그림의 뜻은, 3차원 입력 N개와 3차원 필터 N개로 배치 컨볼루션을 하면 출력으로 2차원 행렬 N개가 쌓여 3차원의 데이터가 나온다는 것이다.
풀링 계층
한편 합성곱을 하지 않고도 데이터의 공간을 줄이는 연산이 존재한다. 이를 풀링(Pooling)이라고 한다. pool은 ‘공동으로 모으다’라는 뜻이 있는데, 여기서 나온 용어이다.
뭘 모으냐? 앞서 필터와 같이 행렬을 구획짓는 영역을 윈도우(window)라 하는데, 각 윈도우를 필터 없이 하나의 대푯값만으로 남기는 연산이다.

다음은 가장 기본적인 스트라이드 2짜리 최대 풀링(max pooling; 맥스 풀링)을 나타낸 것인데, 2*2 윈도우 안에서 가장 큰 원소만을 골라 추려내는 연산이다.
이 외에도 평균 풀링(average pooling)과 최소 풀링(min pooling) 등도 존재하지만, 이 최대 풀링이 일반적이다. 풀링은 그 윈도우의 크기와 스트라이드의 크기를 같게 설정한다(여기선 모두 2)
풀링은 학습해야 할 매개변수가 없고, 채널 수(C)가 변하지 않는다는 특징도 있지만, 가장 중요한 것은 입력 데이터의 변화에 강하다라는 것이다.

다음과 같이 데이터가 한 칸씩 오른쪽으로 이동되는 변형이 일어났다고 하자. (쉽게 말해 사진을 조금 왼쪽까지 보이도록 자른것이다.) 아무리 움직였다 하더라도 기존의 윈도우 안에 옮겨진 최대값들이 모두 들어가기에, 출력 피처 맵은 바뀌지 않는 것을 볼 수 있다. 즉 변화에 강건하다.
CNN(합성곱 신경망)
위에서 Convolution Layer와 Pooling Layer를 배웠다. 이제 둘을 합쳐서 합성곱 신경망(CNN; Convolution Neural Network)을 구성해보자. CNN의 구성은 다음과 같이 나타낼 수 있다.

기존 Affine 계층을 없애고 합성곱 계층을 넣는다. 또 활성화함수(여기선 ReLU) 계층 다음에 풀링 계층을 넣어 크기를 변환해주고 다음으로 넘겨준다.
여기서 아직 Affine 계층이 남아있는 것을 볼 수 있는데, 이미지 처리의 최종 목표가 MNIST와 같이 확률을 통한 분류인 경우, 마지막에 Softmax를 넣기 위해 FC Layer를 남겨놓거나 추가로 삽입할 수도 있다.
합성곱 계층 구현
이제 합성곱 계층을 구현해볼 차례인데, 먼저 im2col(image to column) 함수를 배워야한다. im2col은 3차원 이미지나 배치처리를 위한 4차원 데이터를 2차원 행렬로 전개하는 함수로, 다음과 같이 처리된다. (im2col과 역전개인 col2im은 임포트하는 것으로 대체한다)
# im2col 사용해보기
import os, sys
sys.path.append('/content/drive/<여기에 주소 입력>') # 내가 저장한 구글 드라이브 위치
import numpy as np
# common 파일: 옮긴이 깃허브 -> 내 작업 파일로 이동
from common.util import im2col, col2im
x1 = np.random.rand(1, 3, 7, 7) # (데이터 수, 채널 수, 높이, 너비)
col1 = im2col(x1, 5, 5, stride=1, pad=0) # (input_data, filter_h, filter_w, stride=1, pad=0)
"""7*7 이미지에 패딩없이 5*5 필터를 스트라이드 1짜리로 합성곱을 하면 3*3 행렬(A)이 나온다
이 A의 원소 9개를 행으로 놓고, 각각 합성곱 처리된 3*5*5(5*5 필터 3개)개의 원소를 각 행에 1줄로 넣는다"""
print(col1.shape) # (9, 75)
x2 = np.random.rand(10, 3, 7, 7) # 3*7*7짜리 데이터 10개
col2 = im2col(x2, 5, 5, stride=1, pad=0)
"""7*7 이미지에 패딩없이 5*5 필터를 스트라이드 1짜리로 합성곱을 하면 3*3 행렬(B)이 나온다
따라서 행렬 B 하나당 원소는 9개인데, 이런 3차원 데이터가 10개가 들어와 4차원데이터가 흐르므로
행은 9*10개가 되고, 열은 각각 합성곱 처리된 75(5*5 필터 3개)개의 원소를 각 행에 1줄로 넣는다"""
print(col2.shape) # (90, 75)
주석으로 달은 것처럼 출력 행렬의 행은 ‘3차원 데이터의 개수(N) * 합성곱 행렬의 원소 수(OH * OW)’이고 열은 ‘채널 수(C) * 필터의 세로 크기(FH) * 필터의 가로 크기 (FW)’이다. 즉 각 합성곱의 결과를 하나의 행으로 만들어서 일렬로 쭉 쌓아내려간 것!
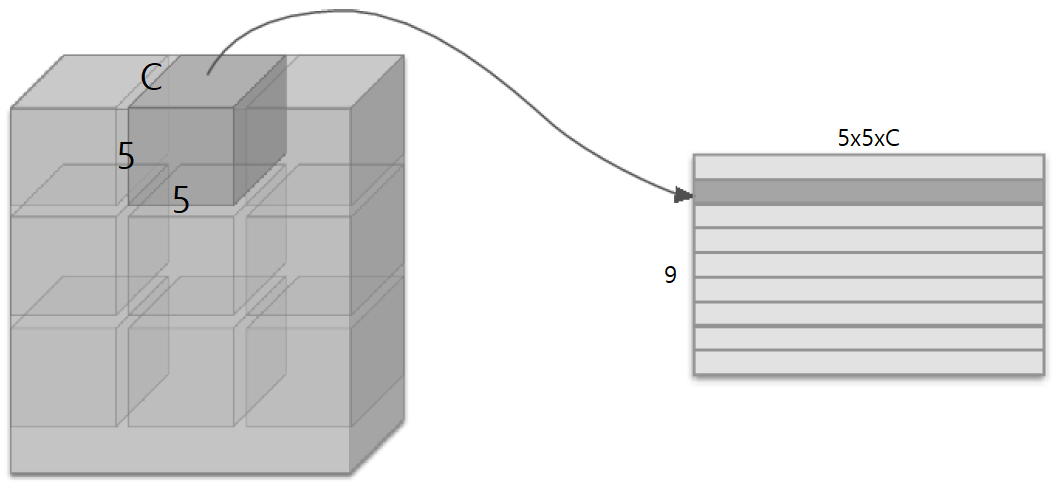
이미지로 시각화하면 다음과 같은데, 아마 바로 이해하긴 어려울 것이다. 계속 봐 보시길.. 참고로 필터 적용 영역이 저렇게 딱 떨어지지는 않는다. (물론 스트라이드를 필터의 크기와 같게 설정한다면 딱 떨어지겠지만) 보통 영역이 겹치기 마련이다.
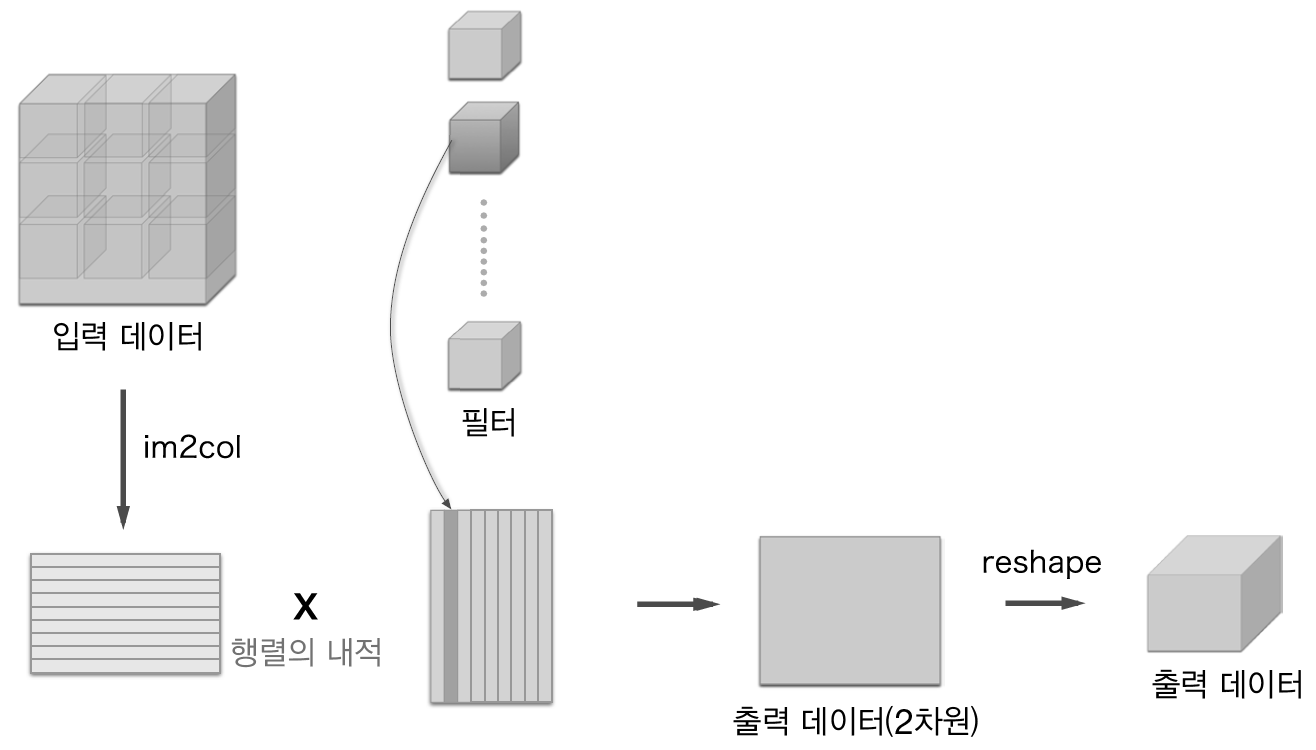
아무튼 저렇게 펼쳐진 입력 데이터를 가중치 행렬(필터를 펼친 것)과 곱하여 출력 데이터를 내놓는다. 실제로 Convolution 클래스를 구현하면 다음과 같다.
# 합성곱 계층 Convolution 클래스의 순전파/역전파 모두 구현
class Convolution:
def __init__(self, W, b, stride=1, pad=0):
self.W = W # 생성 시 필터 입력 받음
self.b = b # 생성 시 편향 입력 받음
self.stride = stride
self.pad = pad
# 중간 데이터(backward 시 사용)
self.x = None
self.col = None
self.col_W = None
# 가중치와 편향 매개변수의 기울기
self.dW = None
self.db = None
def forward(self, x):
FN, C, FH, FW = self.W.shape # 생성 시 초기화된 필터의 크기
N, C, H, W = x.shape # 입력받은 데이터의 크기
out_h = 1 + int((H + 2*self.pad - FH) / self.stride)
out_w = 1 + int((W + 2*self.pad - FW) / self.stride)
# 1단계: im2col
col = im2col(x, FH, FW, self.stride, self.pad) # 입력데이터를 전개
col_W = self.W.reshape(FN, -1).T # 필터를 전개
# 2단계: Affine
out = np.dot(col, col_W) + self.b # 2차원의 출력 데이터
# 3단계: Reshape
"""2차원 출력 데이터를 (데이터 수, 높이, 너비, 채널 수)의 4차원으로 reshape한 후
전치(transpose)를 시켜 (데이터 수, 채널 수, 높이, 너비)로 변환"""
out = out.reshape(N, out_h, out_w, -1).transpose(0, 3, 1, 2)
self.x = x # 역전파를 대비하여 저장
self.col = col
self.col_W = col_W
return out
def backward(self, dout):
FN, C, FH, FW = self.W.shape
# 1단계: Reshape의 역전파
dout = dout.transpose(0,2,3,1).reshape(-1, FN)
self.db = np.sum(dout, axis=0)
# 2단계: Affine의 역전파
self.dW = np.dot(self.col.T, dout)
self.dW = self.dW.transpose(1, 0).reshape(FN, C, FH, FW)
# 3단계: im2col의 역전파 = col2im
dcol = np.dot(dout, self.col_W.T)
dx = col2im(dcol, self.x.shape, FH, FW, self.stride, self.pad)
return dx
여기서 순전파(forward)를 보면 im2col을 거친 이미지 ‘col’과 필터를 전개한 ‘col_W’을 내적한 후 편향을 더하여 결괏값이 나옴을 확인할 수 있다. 이때 다시 out을 reshape 및 전치(transpose)해주는데, 이는 2차원 데이터를 4차원으로 다시 되돌려놓고, 입력 데이터와 같이 (N, C, H, W)의 형식으로 복원시켜주는 과정이다.
한편 역전파(backward)에 대하여서는 설명하지 않았는데, 과정을 보면 순전파의 단계와 정반대로 레이어를 거쳤음을 확인할 수 있다.
그 이유는 Convolution = im2col + Affine + reshape이기 때문인데, 자세한 계산 과정은 한 교수님의 설명 영상을 달아두겠다. 중간까지는 봤는데, 너무 길고 나도 요즘 지쳐서 패스.. 나중에 끝까지 봐보자.
풀링 계층 구현
풀링도 전개과정은 im2col과 col2im을 사용하고, 다만 맥스 풀링의 경우 최댓값을 구한 후 형상변형(reshape 및 transpose)을 한다는 차이가 있다.
# 풀링 클래스 구현 (역전파 구현은 패스)
class Pooling:
def __init__(self, pool_h, pool_w, stride=1, pad=0):
self.pool_h = pool_h # 풀링 높이
self.pool_w = pool_w # 풀링 너비
self.stride = stride # 풀링 보폭. 보통 높이/너비와 같게 설정
self.pad = pad
def forward(self, x):
N, C, H, W = x.shape
out_h = int(1 + (H - self.pool_h) / self.stride)
out_w = int(1 + (W - self.pool_w) / self.stride)
# 전개 (1): 여기까진 컨볼루션의 im2col와 같다
col = im2col(x, self.pool_h, self.pool_w, self.stride, self.pad)
col = col.reshape(-1, self.pool_h * self.pool_w)
# 최댓값 (2): 행별로 최댓값을 구함
out = np.max(col, axis=1)
# 성형 (3) : 출력데이터의 형상으로 변형
out = out.reshape(N, out_h, out_w, C).transpose(0, 3, 1, 2)
return out
CNN 구현
이제 단순한 CNN 네트워크를 구성해볼 건데, 앞선 풀링 클래스에서 역전파 구현을 하지 않았기에 실제 CNN을 돌릴 수는 없다. 궁금한 사람은 옮긴이 깃허브를 참조하자.
# 단순 CNN 구현(Conv-ReLU-Pooling ~ Affine-ReLU ~ Affine-Softmax)
from collections import OrderedDict # 각 계층들의 통과 순서를 지정하기 위해 임포트
class SimpleConvNet:
def __init__(self, input_dim=(1, 28, 28), conv_param ={'filter_num':30, 'filter_size':5, 'pad':0, 'stride':1},
hidden_size=100, output_size=10, weight_init_std=0.01):
filter_num = conv_param['filter_num']
filter_size = conv_param['filter_size']
filter_pad = conv_param['pad']
filter_stride = conv_param['stride']
input_size = input_dim[1]
conv_output_size = (input_size - filter_size + 2 * filter_pad) / filter_stride + 1
pool_output_size = int(filter_num * (conv_output_size / 2) * (conv_output_size / 2))
self.params = {}
# 행과 열의 개수가 모두 filter_size로 같은 정방행렬
self.params['W1'] = weight_init_std * np.random.randn(filter_num, input_dim[0], filter_size, filter_size)
self.params['b1'] = np.zeros(filter_num)
self.params['W2'] = weight_init_std * np.random.randn(pool_output_size, hidden_size)
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b3'] = np.zeros(output_size)
# CNN을 구성하는 계층
self.layers = OrderedDict()
self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'], conv_param['stride'], conv_param['pad'])
self.layers['Relu1'] = Relu()
self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2) # 풀링 행, 열, 보폭이 모두 같다(이게 일반적임)
self.layers['Affine1'] = Affine(self.parmas['W2'], self.params['b2'])
self.layers['Relu2'] = Relu()
self.layers['Affine2'] = Affine(self.params['W3'], self.params['b3'])
self.last_layer = SoftmaxWithLoss() # SimpleConvNet의 마지막 계층 프로퍼티를 선언
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
y = self.predict(x)
return self.lastLayer.forward(y, t)
def gradient(self, x, t):
# 순전파
self.loss(x, t)
# 역전파(Pooling의 backward() 메소드 미구현으로 실행 불가)
dout = 1
dout = self.lastLayer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layers.backward(dout) # Pooling 역전파를 구현해야 실행 가능
# 결과 저장
grads = {}
grads['W1'], grads['b1'] = self.layers['Conv1'].dW, self.layers['Conv1'].db
grads['W2'], grads['b2'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W3'], grads['b3'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads
대표적인 CNN
지금 소개하는 건 모두 이미지 인식에 대한 CNN이다. 대표적으로 LeNet과 AlexNet이 있다.
LeNet
1998년이라는 다소 예전에 제안됐던 LeNet(르넷)은 앞서 다룬 CNN에서 ReLU 대신 sigmoid를 사용하고, 맥스 풀링이 아닌 서브샘플링을 한다는 차이점을 빼고는 크게 이해하는 데에 어렵지 않다.

현재의 CNN이 더 효과가 좋긴 하지만, 무려 26년 전에 제안된 첫 CNN이라는 의미가 있기에 현재까지도 배운다.
AlexNet
비교적 최근(?이라고 하기엔 십여년 전..)에 나온 AlexNet은 LeNet에서 활성화함수를 ReLU로 바꾸고 국소적 정규화(LRN)와 드롭아웃을 적용했다는 차이가 있다. 자세한 건 나중에 배워보고 일단 구성도만 봐보자.
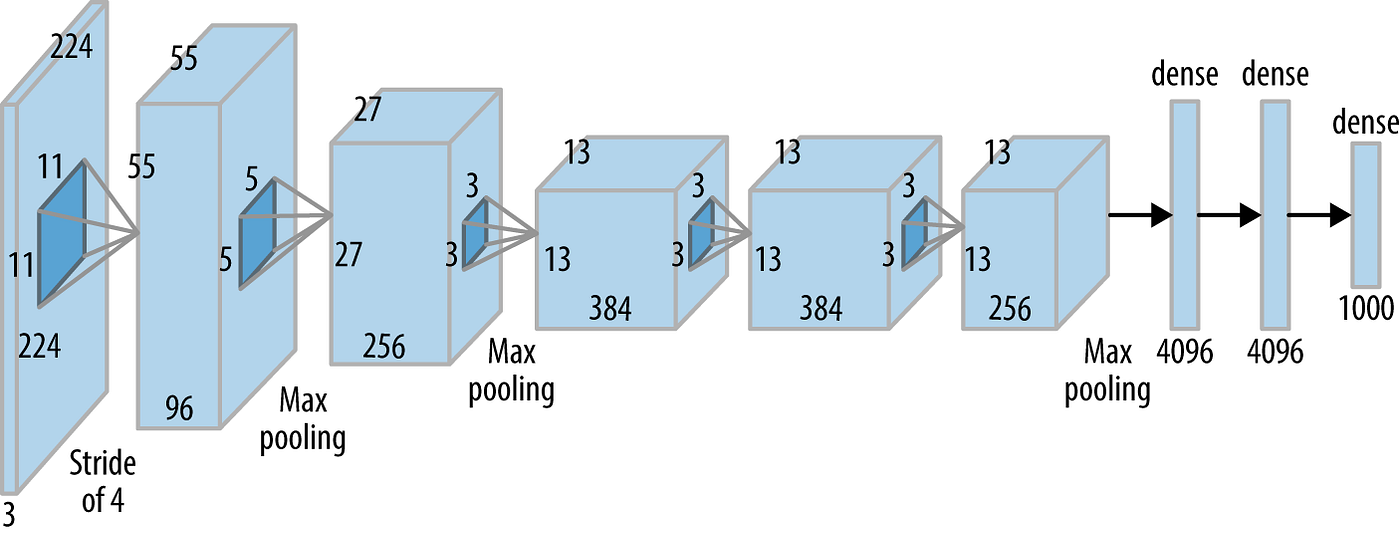
이 CNN들은 해마다 대회를 통해 더 좋은 성능의 신경망들이 개발되고 있는데, 널리 알려진 것들이 VGGNet, GoogLeNet, ResNet 등이다. 이래서 현직자들이 매년 새로운 논문을 보는가보다.

출처: [밑바닥부터 시작하는 딥러닝 Chapter 7]