[Deep Learning 7] CNN 기반 딥러닝
이제 책의 마지막 장이다. 오늘 반납일인데 포스팅하느라 하루 연체해야할 듯. 오늘 안에 부록 A 내용까지 다루고 내일 아침 반납하러 가야겠다~ 이거 말고 부산 여행 등등 계획도 세우고!
CNN을 개선하는 방법
먼저 층을 깊게 하는 방법이 있다. 이것이 층을 무작정 깊게 할수록 좋다는 말은 아니고, 같은 네트워크를 만든다면 필터를 조금 작게(3*3 정도?) 하고 대신 그 필터를 여러 번 통과시키는 것이 낫다는 얘기.
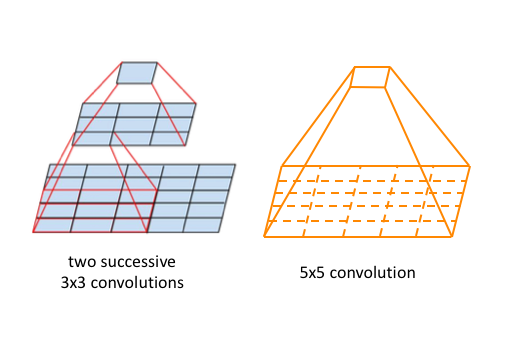
왼쪽은 크기 3짜리 필터를 두 번 통과시킨 것이고, 오른쪽은 크기 5짜리 필터를 한 번 통과시킨 것이다. 모두 5*5 짜리 행렬을 하나의 값으로 요약하였다. 이처럼 최종 요약된 영역을 수용 영역(receptive field)이라고 한다.
양쪽 다 수용 영역이 5행5열의 정방행렬이지만, 왼쪽은 필터의 크기가 3이기에 매개변수가 원소 9개짜리 필터가 2개라서 총 매개변수가 18개이다. 반면 오른쪽은 원소 25개짜리 필터 하나를 사용하므로 매개변수가 25개로 늘어나게 된다.
따라서 같은 수용 영역을 처리하는데 매개변수가 더 적게끔 크기 3짜리의 작은 필터를 여러번 통과시키는 것이다. 다만 크기 2짜리 필터는 인식 저하가 일어날 수 있어 사용하지 않고, 보통 3짜리 필터를 사용한다고.
또 GPU 컴퓨팅을 활용해 분산 학습(수평 확장; scale out)을 하거나 실수형의 정밀도를 낮추는 방법, 훈련 데이터를 인위적으로 변형하여 데이터 확장(data augmentation)을 하는 방법도 있다.
최근의 CNN 역사
이전 포스팅에서 다룬 AlexNet에 이어서 더 발전한 CNN들을 봐보자.
VGGnet
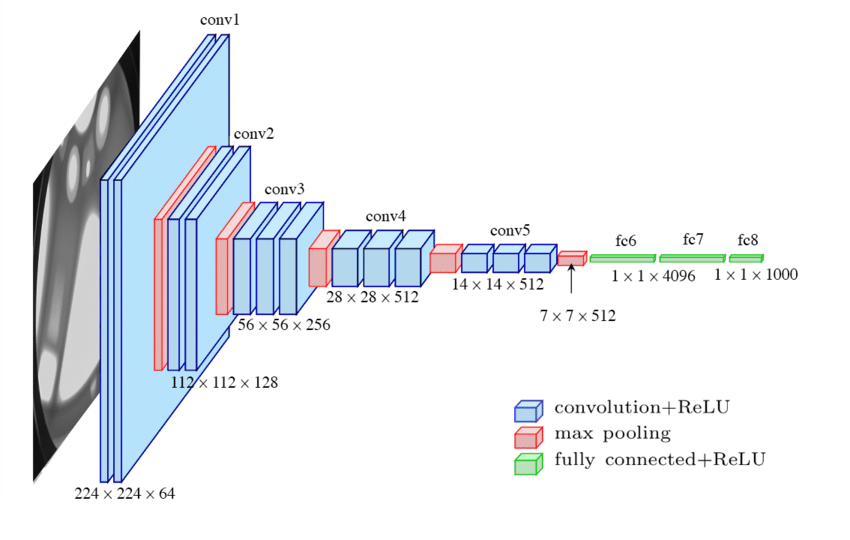
2014년 ILSVRC라는 대회에서 2등을 차지한 VGG16이다. 중간의 층 개수가 더 많은 VGG19도 존재한다.
VGG16의 특징은 매 Convolution(파란색)에서 입력과 출력의 형상이 동일하다는 것이다. 3*3 필터를 사용하는데 어떻게 형상이 줄어들지 않냐고? 항상 zero padding을 1씩 사용하기 때문에 필터의 크기와 상쇄되어서 같은 출력이 나오는 것
\[OH=\frac{H+2P-FH}{S}+1\] \[OW=\frac{W+2P-FW}{S}+1\]지난 장에서 다뤘던 수식인데, 여기서 P=1, FH=FW=3, S=1을 대입하면 OH=H, OW=W가 나와서 같은 크기가 유지됨을 확인할 수 있다.
크기를 축소시키는 것은 2*2의 맥스 풀링으로만 이루어지고, 마지막에 FC layer를 사용함으로써 결과를 출력한다. 구성이 간단하여 응용이 쉽고 널리 사용되는 편
GoogLeNet
구글넷인데 중간의 L을 대문자로 표기하는 센스있는 작명이다.
구글넷은 인셉션 구조라는, 깊이와 함께 폭도 늘린 설계를 사용한다. 각각 크기가 다른 컨볼루션들을 적용하여 이 필터들을 하나로 결합하는 방식이다. 2014년 1등
ResNet
이번엔 구글의 경쟁사 마이크로소프트에서 개발한 ResNet(Residual Network)이다. 특이하게 이 신경망은 연결 그래프로 주로 표현된다.
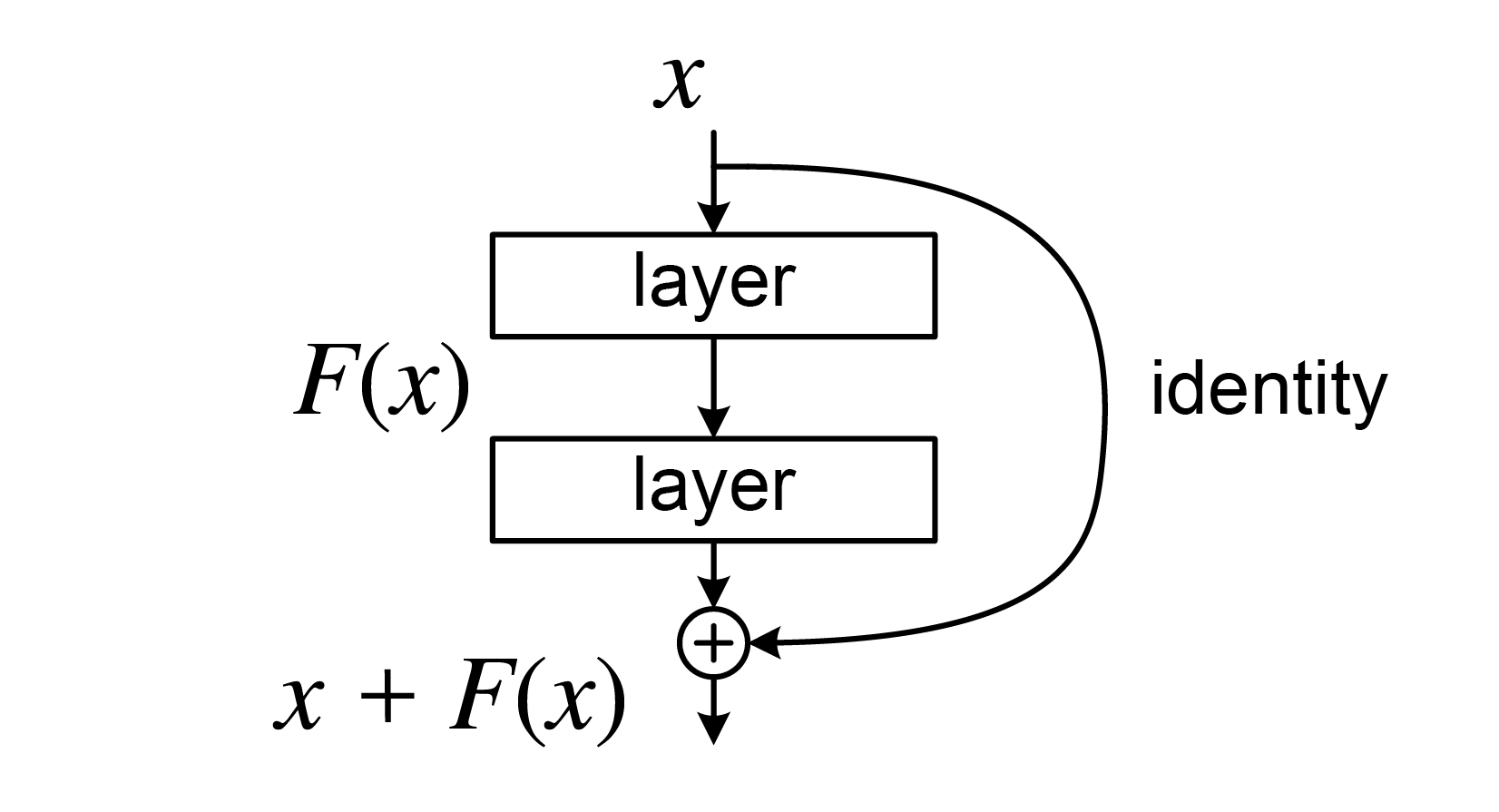
도식을 보면 입력 데이터 x를 한 번은 컨볼루션을 두 번 적용하여 F(x)를 만들고, 한 번은 항등함수를 통과시켜(즉 아무 처리도 안하고 그대로) x라는 값을 내온다. 그리고 둘을 더하는 신기한 설계. 이처럼 항등함수를 통과시켜 값을 그대로 흘려보내는 것을 스킵 연결(skip connection)이라 한다.

보면은 2개 층마다 하나는 그대로 컨볼루션을 통과, 하나는 건너뛰면서 층을 늘린다. ResNet은 2015년 1등으로 Top-5 오류율이 3.5%에 불과하다.
CNN의 활용
지금까지는 이것이 무슨 사물일지 판단하는 ‘사물 인식’만을 이 책에서 다뤘지만, 사실 딥러닝은 그 이상의 ‘사물 검출’과 분할, 캡션(멘트 생성)에도 적용이 가능하다. 여기부터는 RNN의 영역인데 아직 공부를 제대로 못해봐서 이건 나중에 RNN을 공부할 때 다뤄보겠다.
최근에는 이미지뿐만 아니라 아예 이미지를 연속하여 화풍에 맞는 영상도 만들어주는 경지에 이르렀다. 앞서 말한 사물 검출과 분할을 기반으로 자율 주행을 수행하기도 하는 등 딥러닝의 끝은 없는 듯~
출처: [밑바닥부터 시작하는 딥러닝 Chapter 8]